Lab 4 : Multitasking¶
Introduction¶
Multitasking is the most important feature of operating systems. You’ll learn how to implement the basis of multitasking and understand how user mode and kernel mode interact in depth.
The multitasking mechanism in this lab works without virtual memory which is common for MMU-less devices. You can build up a basic concept of multitasking, and you’ll reimplement it after we introduce how virtual memory works in the next lab.
Goals of this lab¶
Understand how to create tasks.
Understand how tasks get scheduled and context switch.
Understand how to design system calls.
Understand how to design signal mechanism.
Understand how to design lock and wait mechanism.
Understand how to design preemptive kernel
Background¶
This section provides the basis for this lab.
You don’t have to read it through in the beginning. Instead, you can just skim it and go back to this section for details when you get into troubles.
Memory layout¶
You don’t have to care a lot about memory layout in the single-task case. In multitasking, the kernel is responsible for switching the context between tasks. Hence, you should pay more attention to how registers and stack pointer should be modified.
Here, we provide a simple memory layout for you in this lab. It’s just a reference, you can still devise it yourself.
+------------------+
| Arm Peripherals |
+------------------+ <- 0x40000000
| GPU Peripherals |
+------------------+ <- 0x3f000000
| . |
+------------------+
| User stack[n] |
+------------------+
| . |
| . |
+------------------+
| User stack[0] |
+------------------+
| Kernel stack[n] |
+------------------+
| . |
| . |
+------------------+
| Kernel stack[0] |
+------------------+
| Interrupt stack |
+------------------+
| kernel/user bss |
+------------------+
| kernel/user data |
+------------------+
| kernel/user text |
+------------------+ <- kernel_base
Privilege tasks & User tasks¶
Your kernel should support privilege tasks and user tasks. They are mostly in common with some key differences. Specification lists below.
Privilege Task¶
Always run in the the kernel mode.
Doing miscellaneous jobs that should be done in the kernel mode with independent task context.
User Task¶
Mostly run user code in the user mode.
Run in the kernel mode if exceptions taken.
Has its own user mode’s context and the user mode’s context should be saved and restored when enter and exit the kernel mode.
In Common¶
Have its own kernel stack.
Context switch in kernel mode.
Queue in the same runqueue.
In short, privilege task and user task are almost the same except that user task has user context and is able to return to user mode.
Runtime state¶
To help you quickly understand how to design a multitasking kernel, We summarize the runtime into 5 different states. You should follow the description to implement your kernel.
(1) Task is running in user mode
Normally, a user task runs user code in the user mode.
(2) Task is at the entry/exit of a kernel routine
A user task entered kernel mode and already saved its registers for the remaining kernel routine, or
A user task finished the kernel routine, and about to restore its registers and return to user mode.
(3) Task is running a kernel routine
A privilege/user task is running a kernel code with its own kernel stack.
(4) Task is running in the interrupt context
Either when user or privilege tasks are running, interrupt might happen. It’s a special case because the interrupt context does not belong to any tasks.
(5) Context switch state
A task switching happens here, kernel enter this state because voluntarily yield or get preempted at the end of ISR.
The following transition diagram visualize the specification. It also colors the transition should be finished in which step.
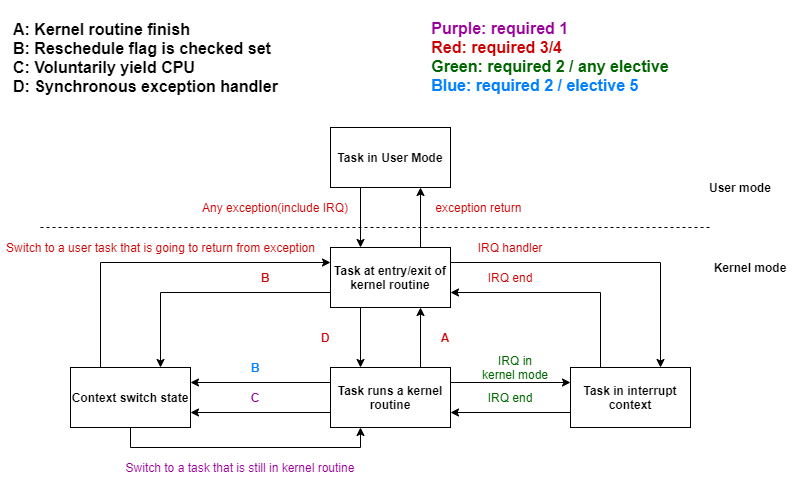
Note
You don’t have to use another interrupt stack for ISR, but you should know interrupt context is different from task context. You should not reschedule inside ISR.
Required¶
Continue from lab3¶
In the last lab, you already implement the interrupt and system call mechanism and run your shell in EL0. Now, let’s move back a little bit. In the beginning of lab4, your interrupt stay disabled and you stay at EL1 without running shell in the booting stage. Of course, you should still set up UART to print debug message.
Note
For the required part, you can disable interrupt when you are in EL1, it simplifies the design and makes debugging easier.
Requirement 1¶
Design your own task struct¶
Task struct (or process control block) is a data structure fore keeping a task’s information. It could include a lot of things such as task id, task status, cpu state, context of task… You should design your own task struct to help kernel context switch between each tasks.
required 1-1 Design your own task struct with at least one field called task id. Task ids should be unique.
Note
You don’t have to make your task struct perfect or complete at the first time. You can define a minimum one, and refine it everytime you find that you need to keep certain information in it.
Hint
For simplicity, you can statically allocate a task struct pool such as struct task task_pool[64];, and set the task id as the index of pool.
Create privilege tasks¶
Now, you can create tasks.
Let’s start from creating privilege tasks.
You need to implement the function privilege_task_create(void(*func)())
It’ll allocate one task struct and one kernel stack.
The created privilege task start at the provided function pointer func and use the allocated kernel stack for its private usage.
required 1-2 Implement privilege_task_create.
Hint
You may statically allocate a kernel stack pool such as char kstack_pool[64][4096], and allocate it according to the task id.
Context Switch¶
It’s time to test if the above functions work well.
You should implement context_switch(struct task* next) to switch between each task.
You need to save the current task’s context and restore the next task’s context.
You can create two privilege tasks after kernel initialization.
Each one will print some message, delay a period of time, and call context_switch to switch the other one.
required 1-3 Implement context_switch.

// This is example for a simple context switch, you should change it according to your task struct design.
.global switch_to
switch_to:
stp x19, x20, [x0, 16 * 0]
stp x21, x22, [x0, 16 * 1]
stp x23, x24, [x0, 16 * 2]
stp x25, x26, [x0, 16 * 3]
stp x27, x28, [x0, 16 * 4]
stp fp, lr, [x0, 16 * 5]
mov x9, sp
str x9, [x0, 16 * 6]
ldp x19, x20, [x1, 16 * 0]
ldp x21, x22, [x1, 16 * 1]
ldp x23, x24, [x1, 16 * 2]
ldp x25, x26, [x1, 16 * 3]
ldp x27, x28, [x1, 16 * 4]
ldp fp, lr, [x1, 16 * 5]
ldr x9, [x1, 16 * 6]
mov sp, x9
msr tpidr_el1, x1
ret
.global get_current
get_current:
mrs x0, tpidr_el1
#define current get_current();
extern struct task* get_current();
void context_switch(struct task* next){
struct task* prev = current;
switch_to(prev, next);
}
Scheduler¶
It’s hard for tasks to know which task it suppose to switch to , so you need a scheduler. The scheduler finds the next task to be run and context switch to it.
Put task into runqueue¶
There are runnable tasks and non-runnable tasks. You can create a data structure called runqueue for CPU. Runnable tasks will be put into runqueue and scheduler can pick one from runqueue and switch to it.
required 1-4 In the end of privilege_task_create, put the task into the runqueue.
Schedule a task¶
After runnable tasks are in the runqueue, you can use an arbitrary scheduling algorithm to pick a task from runqueue. You need to implement a round-robin scheduling algorithm in this lab.
After you have your own scheduler and runqueue, you should provide a function call schedule().
It picks the next task according to it scheduling policy and use context_switch to switch to it.
required 1-5 Replace context_switch with schedule in the privilege tasks, you should be able to create more than 2 tasks and switch between them.
Idle task¶
Idle task is always runnable. When there is no other runnable task, it get scheduled and run to prevent a non-deterministic state of CPU.
Hint
You may statically define a startup privilege task, and the task do the following jobs
Setup the kernel after booted by GPU.
Call
privilege_task_createto create the second task.Enter idle state, and now the startup task becomes the idle task.
In idle state, repeatly call
schedulein an infinite loop, the idle task get switched out if there is another runnable task.
Pitfall¶
If you don’t implement preemptive kernel, privilege tasks should always explicitly call
scheduleat some time to switch another task. Otherwise, CPU will never run other tasks.Do not return from privilege task’s routine, you should call
exitto end a privilege task. (introduce later)
Runtime state transition example¶
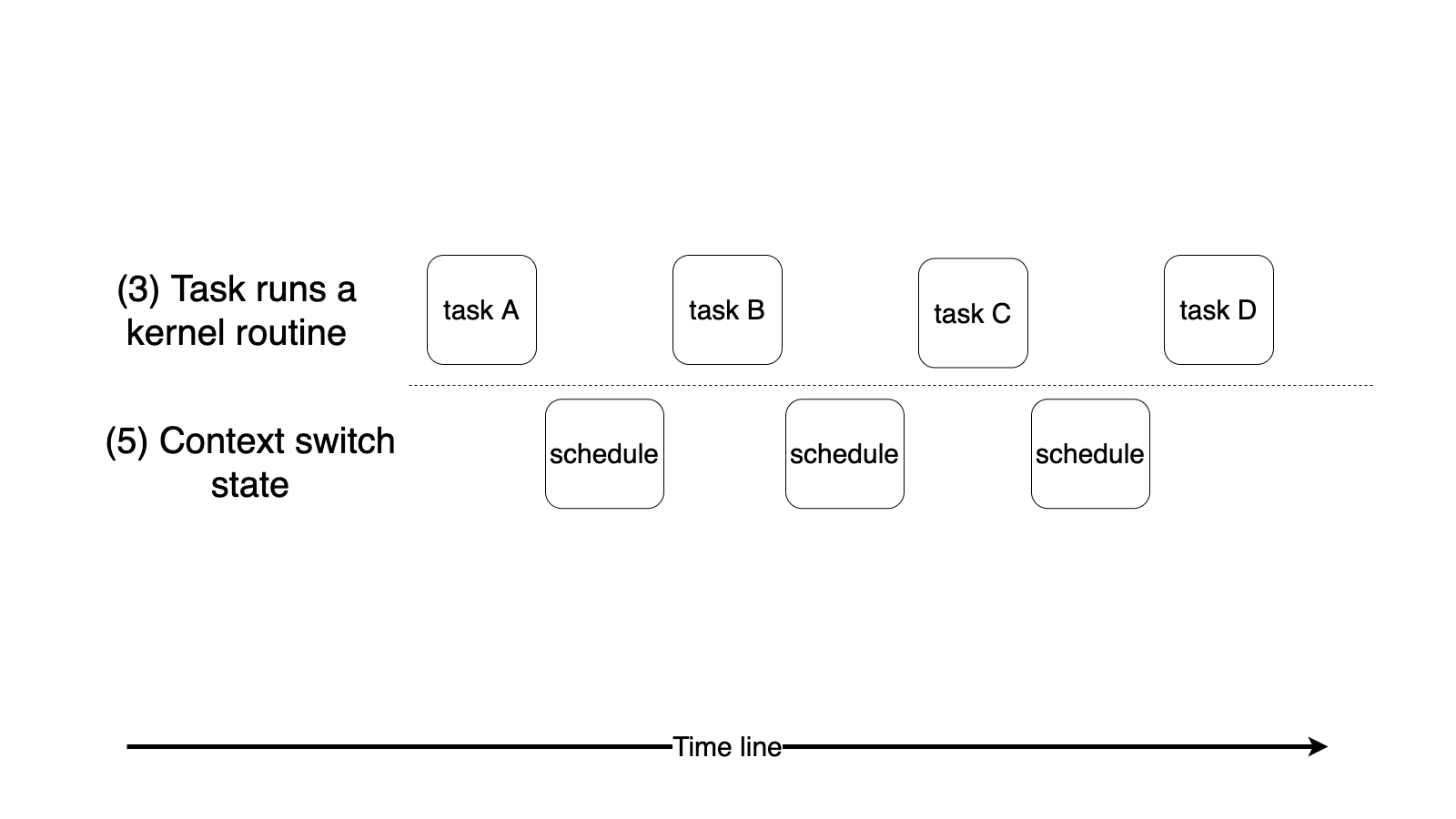
Requirement 2¶
Timer Interrupt¶
Timer interrupts CPU periodically, we can use it for time sharing system.
Timer interrupt handler will update current task’s running time and check if it used up it time in this epoch.
If yes, it sets the reschedule flag of the current task to indicate that task need to call schedule to yield CPU later on.
required 2-1 Reimplement the core timer handler, it updates the current task’s reschedule flag.
required 2-2 Create more than 2 privilege tasks. Each of them keeps checking the reschedule flag. If the flag is set, it prints some message, clears reschedule flag and issue schedule .
Note
You need to enable interrupt in EL1 here to test this requirement’s functionality
After you implement user task( in the later section ), you can disable interrupt in EL1 for simplicity and you can still get the full score for
required.
Runtime state transition example¶
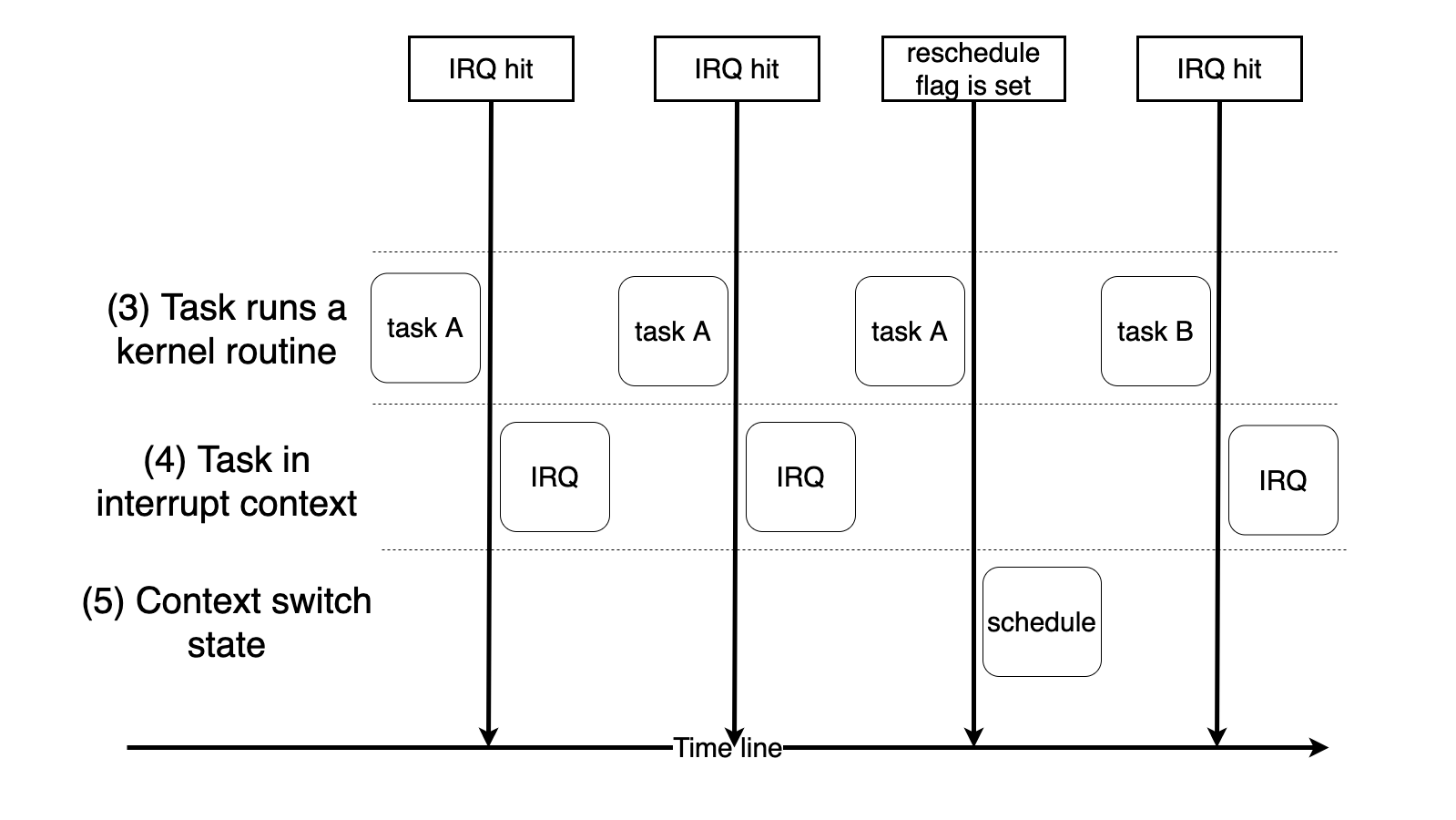
Requirement 3¶
User task¶
Besides privilege tasks, you’ll also need user tasks with less privilege for safety and security.
User mode context¶
You’re going to implement multitasking in user mode now. You already know that user mode’s general registers are saved at the top of kernel stack. Besides, you should also notice 3 user task related system registers.
SP_EL0: The address of user mode’s stack pointer.
ELR_EL1: The program counter of user mode’s procedure.
SPSR_EL1: The CPU state of user mode.
SP_EL0, ELR_EL1, SPSR_EL1 should be properly saved and restored when task’s execution mode switch between user mode and kernel mode.
Also, an user task should have one kernel stack and one user stack. They are used for executing in different modes.
do_exec¶
exec originally takes a program file as argument and execute it.
Currently, filesystem is not implemented, but we still borrow the name with a little bit changed.
Now, you should implement do_exec(void(*func)()) which takes a function pointer to user code.
And it should set up the task’s user context.
required 3-1 Implement do_exec
Note
After privilege task becomes user task, it should be able to go to runtime state (2) mentioned in Runtime state
Kernel mode also use ELR_EL1 and SPSR_EL1 during exception and interrupt handling, don’t mess it up if you enable interrupt in EL1.
User tasks preemption¶
Multitasking in user mode can still be implemented by voluntarily yield the control to other task. A system calls such as sched_yield helps user task to do this. However, it’s inconvienent for user to insert it in their code everywhere. Also, too much or too few yield calls may happens for amateur user code programmer.
Hence, a preemption mechanism provided by kernel is needed for user task. User tasks preemption could be easily implemented as:
When a user task finishes its kernel routine or an ISR and ready to return user mode, it checks the reschedule flag and call schedule() to switch to another task if the flag is set.
required 3-2 Implement user tasks preemption.
Runtime state transition example¶
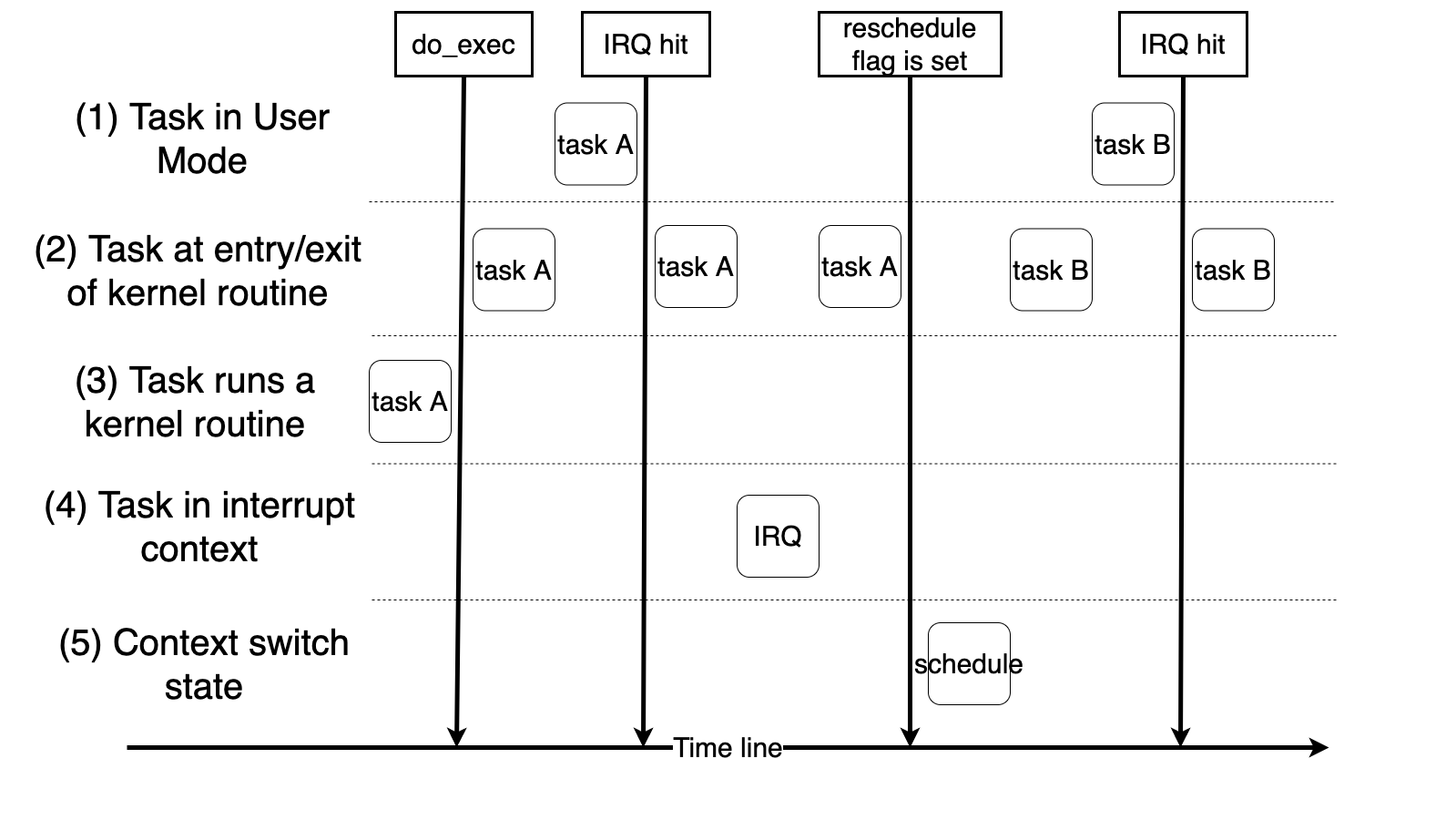
Requirement 4¶
System call¶
You practiced simple system calls in the last lab. Now, You need to extend them.
Trapframe¶
When user task enter kernel mode, it saves registers on the top of its kernel stack. We name it as trapframe.
Trapframe is useful for passing information between user and kernel mode.
User can set registers to be parameters and system call number. After system call into kernel, kernel can read the content from trapframe.
Kernel can set the content of trapframe. After return to user, user get the return value and error number from the restored registers.
System call hierachy¶
System calls are usually implemented with hierachy.
Here, we use get_taskid as an example.
// user program calls the library API.
int main(){
printf("Task id: %d\n", get_taskid());
}
// user library provided API
// system call wrapper for different architectures and operating systems.
.global get_taskid
get_taskid:
mov x8, SYS_GET_TASKID
svc 0
ret
//----------------enter kernel ---------------
void el0_svc_handler(){
if(get_syscall_no(current) == SYS_GET_TASKID){
if(sys_get_taskid() == 0){
} else {
BUG();
}
}
}
// general interface for all system calls in kernel.
// may handle trapframe related things here.
int sys_get_taskid() {
set_trap_ret(do_get_taskid());
return 0;
}
// real working space for a system call.
// may also be called by other kernel functions.
int do_get_taskid() {
return current -> taskid;
}
Warning
It’s just a plain example, you should design it yourself to make it more extensible and more efficient.
Note
As you can see, a system call may have different function names at different hierachy. When a system call appears in the documentation, we use the user library API name in the documentation by default.
I/O system calls¶
I/O devices are shared resources in multiple tasks. It might induce data corruption when user tasks access devices themselves. I/O related system calls let each user task access I/O device as if it has its own one. Kernel should be able to synchronize the I/O requests from different tasks.
In this lab, You need to implement uart_read and uart_write for UART I/O access.
required 4-1 Implement uart_read and uart_write.
Exec¶
A task can call do_exec in kernel mode to set up a new user context.
A system call for do_exec for user mode let user task be able to execute in another user context.
Hence, you need a system call exec to wrap do_exec.
required 4-2 Implement exec.
Fork¶
User task can be created by forking another user task.
The caller of fork is parent and the newly created task is child.
The return value for int fork() should be different from parent and child.
Parent’s return value is child’s task id.
Child’s return value is 0.
Kernel should allocate new task struct and kernel stack for child. Also, parent’s user context should be copied to child’s. But you should modify the trapframe to make the return value different.
required 4-3 Implement fork.
Exit¶
After a task finish its job, it calls exit to release all the resource it has. In the future lab, the resource owned by task is dynamically allocated, the kernel stack of task is, too. It’s hard for a task to release its stack when it need the stack to do the releasing job. So, a exited task should release most of its resource but keepping the kernel stack and task struct. Then, it set its state to be zombie state and won’t be scheduled again.
Note
Privilege task and user task share the common exit call in kernel, but you should provide a system call for user task.
Zombie reaper¶
A task becomes zombie after it exit, a zombie reaper is here to reclaim the remaining allocated resource for zombie task. Zombie reaper could be implemented by
A privilege_task that always check if there are zombie tasks. (Easier)
Each task has its parent task, the parent should use wait function to check and reap zombie child task.
required 4-4 Implement exit and zombie reaper by one of the above methods.
Required system calls summary¶
- size_t uart_read(char buf[], size_t size)
Read size byte to user provided buffer buf and return the how many byte read.
- size_t uart_write(const char buf[], size_t size)
Write size byte from user provided buffer buf and return the how many byte writen.
- int exec(void(*func)())
System call for
do_exec, user context is replace by the provided one.- int fork()
Fork a new user task.
- void exit(int status)
User task exit with status code.
Test cases¶
required 1 and required 2 should be tested by the following code or logic equivelent code.
void foo(){
while(1) {
printf("Task id: %d\n", current -> taskid);
delay(1000000);
schedule();
}
}
void idle(){
while(1){
schedule();
delay(1000000);
}
}
void main() {
// ...
// boot setup
// ...
for(int i = 0; i < N; ++i) { // N should > 2
privilege_task_create(foo);
}
idle();
}
required 3 and required 4 should be tested by the following code or logic equivelent code.
void foo(){
int tmp = 5;
printf("Task %d after exec, tmp address 0x%x, tmp value %d\n", get_taskid(), &tmp, tmp);
exit(0);
}
void test() {
int cnt = 1;
if (fork() == 0) {
fork();
delay(100000);
fork();
while(cnt < 10) {
printf("Task id: %d, cnt: %d\n", get_taskid(), cnt);
delay(100000);
++cnt;
}
exit(0);
printf("Should not be printed\n");
} else {
printf("Task %d before exec, cnt address 0x%x, cnt value %d\n", get_taskid(), &cnt, cnt);
exec(foo);
}
}
// -----------above is user code-------------
// -----------below is kernel code-------------
void user_test(){
do_exec(test);
}
void idle(){
while(1){
if(num_runnable_tasks() == 1) {
break;
}
schedule();
delay(1000000);
}
printf("Test finished\n");
while(1);
}
void main() {
// ...
// boot setup
// ...
privilege_task_create(user_test);
idle();
}
Note
If you have your own testing code and not sure if they are valid, you can paste your testing code on gitter’s discussion room.
Elective¶
In the elective part, you should enable interrupt except some critical regions in EL1. Otherwise, you won’t get any score.
Signal¶
Signal is a short communication mechanism between user tasks. When task A want to send a signal S to task B, A use system call to kernel, and kernel set signal related data structure in B’s task struct. B check its pending signal in kernel mode and it has different handler for different signals.
kill(pid, signal) is the library API to send a signal in POSIX.
You need to implement corresponding system call and pass the information to kernel.
The only signal you need to implement is SIGKILL.
After a user task check its pending signal containing SIGKILL in kernel mode, it kills itself and becomes zombie.
elective 1 Implement kill and signal handler for SIGKILL.
Note
You don’t implement signal handler in user mode in this lab.
question 1 Consider the following POSIX signal example code. Can you elaborate how to design the kernel to support it?
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
void handler(int sig) {
printf("Hello\n");
}
int main()
{
signal(SIGINT, handler);
char buf[256];
int n = read(0, buf, 256);
buf[n] = '\0';
printf("Bye %s\n", buf);
}
Hint
In question 1 you should explain the signal mechanism in 3 parts, signal registration, signal generation, and signal delivery, you can refer to
IMPLEMENTATION OF SIGNAL HANDLING
Priority based scheduler¶
There are important and trivial things in real life, so as in operating system. An idle task can’t share the same amount of time as a task handling brake system of your car. Hence, tasks need to be prioritized.
Priority based scheduler select task according to priority of tasks. Tasks with the same priority will be scheduled in round robin.
elective 2 Implement a priority based scheduler.
Note
Set idle task’s priority to the lowest.
Wait for event¶
Sometimes, user task need blocking read from peripherals. It might induce a long and unpredictable times for a system call handling in kernel. Although you can voluntarily context switch to other tasks when there is no data comes in, you would get a very long runqueue for different tasks waiting for different things. It increase the cost of context switch and redundent scheduling.
Interrupt handler here could help us again. You could maintain a wait queue for a certain event. If a task is waiting for it, it would be removed from the runqueue and join the wait queue. Also, the task’s status would become sleep(block/wait) and waiting for event. The event would be trigger in certain function such as interrupt handler or trigger by other tasks. They’ll will put tasks in wait queue back to runqueue, and the tasks could proceed.
Wait for UART read
UART is a typical example for wait queue. When a task call for uart_read, you should put it into the wait queue if there is no data to be read. In the uart read interrupt handler, it can put the task back to runqueue and the task could read bytes from buffer after getting scheduled.
elective 3 Implement a wait queue for uart reading.
Lock¶
There are several shared resources inside kernel such as allocators, queues and peripherals. When multiple threads modify the same object, it’s possible that the object would be corrupted. Therefore, you need a lock to guarantee that accesses to the object are safe.
mutex¶
Mutex provides mutual exclusive access to an object. If one succeed to acquire the lock, it can proceed and release after the operation is done. Otherwise, it would be block and sleep until someone release the lock and it will try again to acquire the lock.
atomic operation¶
Armv8-A provides ldxr and stxr for exclusive access.
You can either use compiler’s built-in function or hand written assembly.
However, you need to enable MMU and data cache before using the ldxr instruction in real rpi3.
So, you can now use a workaround such as disable preemption in real rpi3 or just give it a trial in QEMU which doesn’t have to enable MMU for ldxr.
elective 4 Implement mutex_lock, mutex_unlock. If task fail to acquire the lock, it would go to sleep and context switch to other tasks.
question 2 Can you prevent all possible context switch by disabling interrupt?
Preemtive kernel¶
Kernel provides system calls for user tasks. When a low priority task call a system call with long execution time. High priority task would still be blocked even it becomes runnanble from sleep. A preemptive kernel could be preempted after interrupt handling. Hence, when an interrupt handler put a higher priority task from wait queue to runqueue, it can be immediately be scheduled. It’s an important trait for real time tasks.
Preemtive kernel could be easily implemented by checking reschedule flag at the end of ISR. However, the tricky part of preemptive kernel is you should be awared about critical region. Otherwise, your data may be corrupted by another kernel routine.
elective 5 Let kernel could be preempted without explicit calling schedule.
question 3 Do you think microkernel need to be preemptive kernel or not? Why or why not?